SubDivNet 学习笔记
这篇文章主要讲述的是如何将卷积神经网络从图像迁移到三维模型中,
从而实现通过使用经典的神经网络模型(如resNet等)实现对三维模型的分类,分割等任务。
相关术语
1. Loop Subdivsion Connectivity
如果一个网格能够用一个更粗糙的网格通过Loop细分得到,则称这个网格拥有Loop Subdivsion Connectivity
2. Loop Subdivsion sequence connectivity
如果有一个网格序列{M0,M1,…,Mn},满足以下两个条件,
- 对于序列中的任意一个网格Mi(i=0)都具有
Loop Subdivsion Connectivity
- 对于任意一个网格Mi(0≤i<n), 该网格中的所有点都存在于下一个网格中Mi+1中
则称这样的一个网格序列具有Loop Subdivsion Sequence Connectivity
网格remesh
SubdivNet方法中由于涉及到池化和超采样两个部分, 所以需要确保当网格变稀疏或者变稠密后,
改变后的网格相较于原始的网格任能够保证一定的联系, 这样能够方便后继的池化和超采样。
remesh的方法参考自论文MAPS: multiresolution adaptive parameterization of surfaces,
其主要思想是先将网格简化, 生成一个网格序列{M0,M1,…,Mn}(其中M0为最粗糙的网格,
Mn为原始网格),并找到原始网格到最粗糙网格的双射Π,
之后通过在M0上做中点细分并映射回Mn完成网格remesh.
网格简化
假定现在有一个网格Mi, 目标是寻找一个简化的网格Mi−1, 可以按照以下步骤寻找
- 算每一个点的权重
通过以下公式计算网格Mi中每一个点的权重W(λ,i)
W(λ,i)=λmaxpi∈Pla(i)a(i)+(1−λ)maxpi∈Plκ(i)κ(i)
其中:
a(i)表示在第i个点的1领域三角面片的面积之和。
κ(i)表示在第i个点上的曲率, 由在该点的两个主曲率(κ1,κ2)相加得到,
即κ(i)=κ1(i)+κ2(i)。
在论文中, λ取值为0.5。
- 去除最大独立点集
找到网格Mi中未标记的权重最小的点, 并标记该点为可去除点, 同时标记其所有邻居点为不可移除点,
循环该过程, 直到标记完所有点, 如下图所示, 其中黑点为去除点。
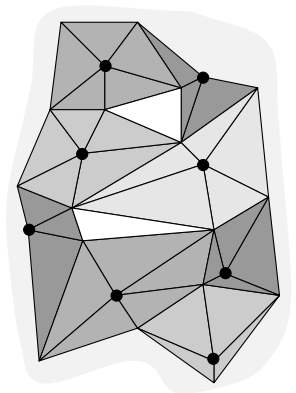
对于点击中的每一个点, 在网格中去除掉该点和与其直接相连的边。
在实际操作的时候, 并不一定会去除掉全部的点, 例如, 假设现在需要保证在下一个网格中总共有i个点,
而现在总共有n个点, 则只需要删除n−i的点。这一点在之后设计网络的时候尤为重要,
因为我们需要保证网络有相同个数的输出以便分类。
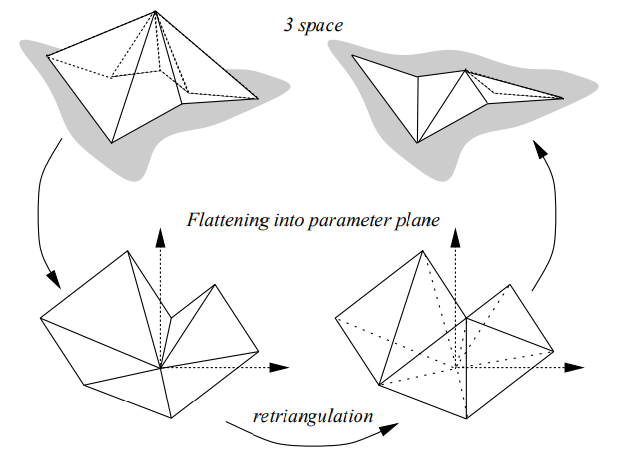
- 在去除点及其1领域附近展开曲面, 并重新三角化
假设映射za表示曲面到平面的映射, 序列{j0,j1,…,jK}表示点i的1领域点,
且面{jk,i,jk+1}是原曲面(移除点之前)的一个三角面片,
用复数μi(pjk)=u+iv表示点jk映射到平面中的位置, 其中u,v表示点jk在平面中的坐标,
pjk表示点jk的三维坐标。对于被去除的点, 其坐标记为(0,0).
使用如下公式计算μi(pjk)
⎩⎨⎧μi(pjk)=rkaexp(iθka)a=2π/θKiθk=∑i=1k∠(pjl−1,pi,pjl)rk=∥pi−pjk∥
之后使用CDT方法在这个二维平面做三角化,并将连接关系映射回原网格即达成了对原网格的一次简化。
下图展示了一次重新三角化的过程
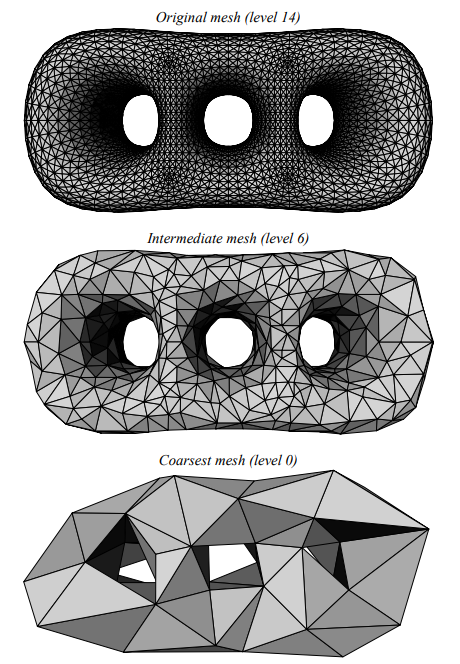
下图展示了对一个曲面多次简化的过程
建立网格映射
为方便期间, 最粗糙网格也被称为基网格
令Π表示原始网格KL到基网格K0之间的双射, 即对于原始网格中的任意一个点p,
都能在K0上找到一个点p0=Π(p)。
令Πl表示原始网格KL到第l层Kl网格之间的双射, 则Πl−1可以用Πl来表示,
具体方法如下
-
如果点i在第l层和第l−1层网络中都存在, 则 Πl−1(pi)=Πl(pi)=pi
-
如果点i在第l层中存在, 但是在l−1层中被移除, 那么在三角化之后,
在第l−1层中一定存在一个三角面片{j,k,m}和重心坐标{α,β,γ},
使得μi(pi)=αμi(pj)+βμi(pk)+γμi(pm),
即Πl−1(pi)=αpj+βpk+γpm。如下图所示。
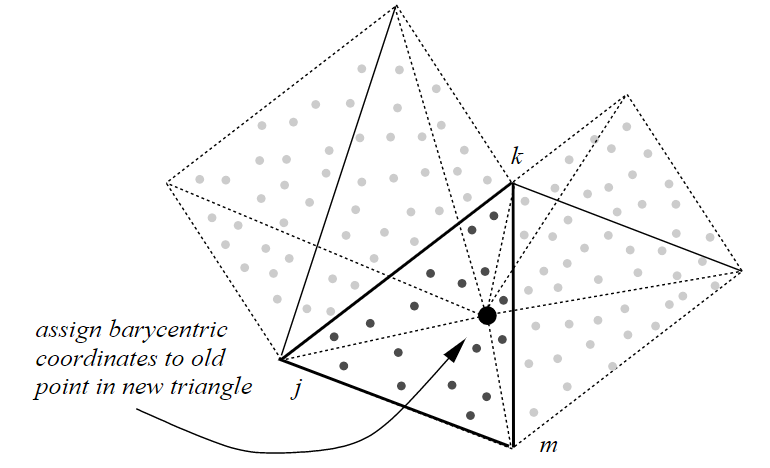
-
如果点i在第l层和第l−1层中都不存在, 那么由2可知,
Πl(pi)=α′pj′+β′pk′+γ′pm′。
其中, {j′,k′,m′}为第l层网格中的点
-
如果{j′,k′,m′}在第l−1层中依旧存在,
则Πl−1(pi)=Πl(pi)=α′pj′+β′pk′+γ′pm′
-
如果{j′,k′,m′}中存在点被移除, 由最大独立点集可知, 这三个点只可能被移除一个,
假设这个点是j′, 由2同理可得,
在第l−1层中一定存在一个三角面片{j,k,m}和重心坐标{α,β,γ},
使得μj′(pj′)=αμj′(pj)+βμj′(pk)+γμj′(pm),
即Πl−1(pi)=αpj+βpk+γpm
Π的作用是为了让原网格中的点都能够用基网格中的三个点来表示。
下图展示了原网格到基网格的映射
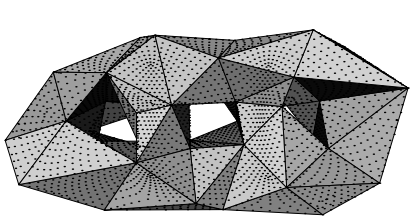
remeshing
remeshing的关键步骤是要建立一个反向映射Π−1, 使得在最粗糙网格个上的点能够映射回原网格。
假设基网格上存在一点q, 而原平面上有一个三角面片{i,j,k}经过Π的映射之后正好包含了点q,
那么点q一定可以表示成如下形式
q=αΠ(pi)+βΠ(pj)+γΠ(pk)
则
Π−1(q)=αpi+βpj+γpk
对基网格上的面片进行三角细分, 之后再运用上面的公式将新的点反向映射到原网格上(去除原网格上的点),
即对于原始网格进行了remeshing
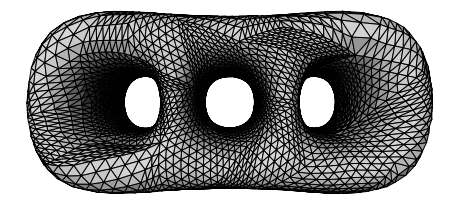
下图展示了remeshing的结果
网格卷积
SubDivNet中的一个重要的任务就是完成了将卷积运用到了三维网格这种非结构化的数据中,
由于卷积原本是运用在二维图像这种结构化的数据之上, 所以必须对传统的卷积进行改进,
以便适应三维网格数据。
卷积层的设计
与图像的卷积不同, SubDivNet中设计的卷积只能够对封闭曲面使用,
且卷积之后网格的大小和拓扑关系都不会发生变化, 改变的仅仅是存储在网格面的特征
基础卷积模板
对于一个面fi, 定义它的基础卷积模板为它的1领域邻居, 如下图所示

之后所有卷积核的设计都是在此基础之上做的衍生
卷积核大小
和二维卷积核的定义相似, SubDivNet定义的卷积核的大小也只能用奇数表示。具体而言,
对于一个大小为k的的卷积核,那么它的大小是它的所有1…2k−1领域面之和, 即
Ω(fi,k)=i=1⋃k^Nk^(fi),k^=2k−1,k=1,3,5,…
下图展示了一个大小为5的卷积核的表示

通过找到其所有1领域和2领域的面来表示这个卷积核
需要注意的是, 当卷积核的大小大于3时, 可能会出现同一个面计算多次的情况, 为了方便,
论文中并没有对这种情况做特殊处理, 并且在设计卷积核的时候通常核的大小不会超过5。
空洞卷积
在设计二维卷积的时候, 有一种常见的设计方法是在计算卷积的时候跳过一些点的计算, 如下图所示

在设计网格的卷积时候, 采用的是一种zig-zag的策略,
简单来说就是不断的通过逆时针-顺时针这样的顺序寻找下一个1领域面, 如下图所示
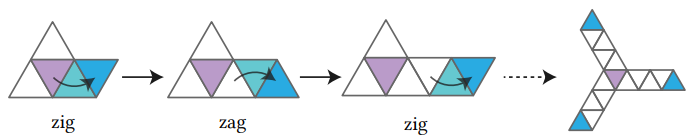
卷积步长
和二维卷积步长不同, 在三维网格中对卷积步长的处理需要用到上述通过remesh建立的网格序列,
假设卷积步长为2, 当前网格(Ml)是由上一层网格通过1:4的细分得到的,
那么就先找到当前面在上一网格(Ml−1)中的对应, 之后在Ml−1中找到它的1领域面,
并将1领域面映射回Ml, 由于是1:4细分, 所以在Ml中有4个面对应, 取中间那个面作为下一个卷积。
一般而言, 如果步长为s, 则要求细分的时候采用的是1:s2的细分方式
卷积的计算
不同于图像中的卷积计算, 卷积核的大小始终等于需要训练的参数的个数,在Subdivnet中,
一个卷积核中需要训练的参数始终是4个
之所以和图像中的卷积大不相同, 是因为网格中卷积的计算必须保证和网格面的输入循序无关,
这么做的目的是为了增加网格的鲁棒性, 具体计算方法如下
Conv(fi)=w0ei+w1j=1∑nej+w2j=1∑n∣ej+1−ej∣+w3j=1∑n∣ei−ej∣
该计算公式适用于k≥3 的情况
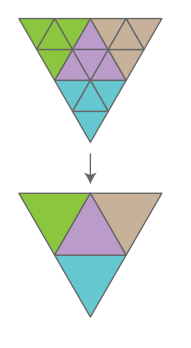
池化
有了上述remesh的之后, 池化的过程将会变得非常简单,
假设当前网格是Ml是通过上一层网格Ml−1通过1:s2的细分得到的,
池化的作用就是将Ml上的特征在Ml−1上重新表现出来。
由于Ml−1层中的每一个面片都能在Ml上找到s2个对应面片,
与图像中的池化一样, Ml−1中这个面的特征由这s2个面片的均值或最大值来表示。
下图展示了一个1:4池化的过程
超采样
超采样可以看作是池化的逆过程, 论文中只讨论了使用1:4进行超采样的过程。
假设网格Ml通过1:4的方式细分成了网格Ml+1, 如下图所示,
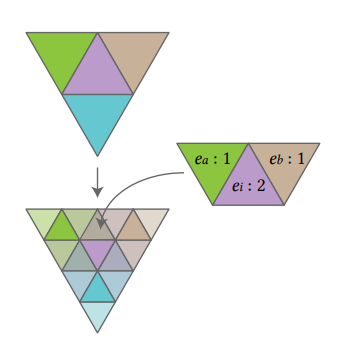
假设面fi被细分成了{fi1,fi2,fi3,fi4}四个面,其中fi4为中心面,
则fi4的特征和fi相等, 即ei4=ei
假设与fi1相邻的两个面分别为fa3和fb1, 它们又是由fa和fb细分得到的,
则fi1的特征ei1=41ea+21ei+41eb
同理可以计算出fi2和fi3的特征
网络结构
在分类任务中, 网络结构是一个k=1的卷积层, 一个归一化层,
一个ReLu层和一个最大池化层之后再重复该结构1次,即为用于分类的网络结构。
用于语义分割的网络是由resnet50 + deeplab v3+结合而成。
网络的输入
每个面上存储的特征是一个13维的向量, 其中7个维度存放形状信息, 6个维度存放姿态信息。
7个形状信息中1个用来存放三角形面积信息, 3个用来存放三个内角信息,
还有3个用来存放面的法向量与三个顶点法向量的内积。
6个姿态信息中3个用来存放面中点的空间坐标, 3个用来存放面的法向量。
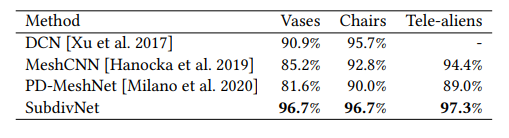
实验结果
分类
数据集
- SHREC11
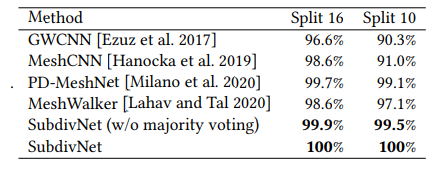
- Cube Engraving
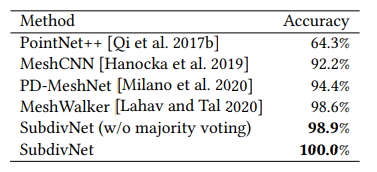
- Manifold40
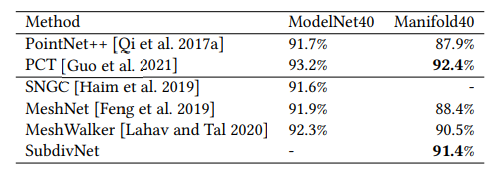
分割
数据集
- human body
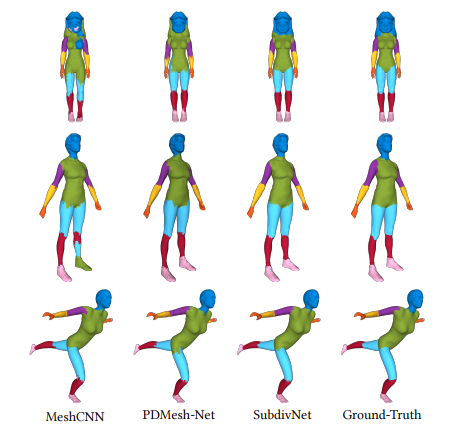
- coseg

 支付宝
支付宝 微信
微信
